https://www.youtube.com/watch?v=X6kCkqQPRvE
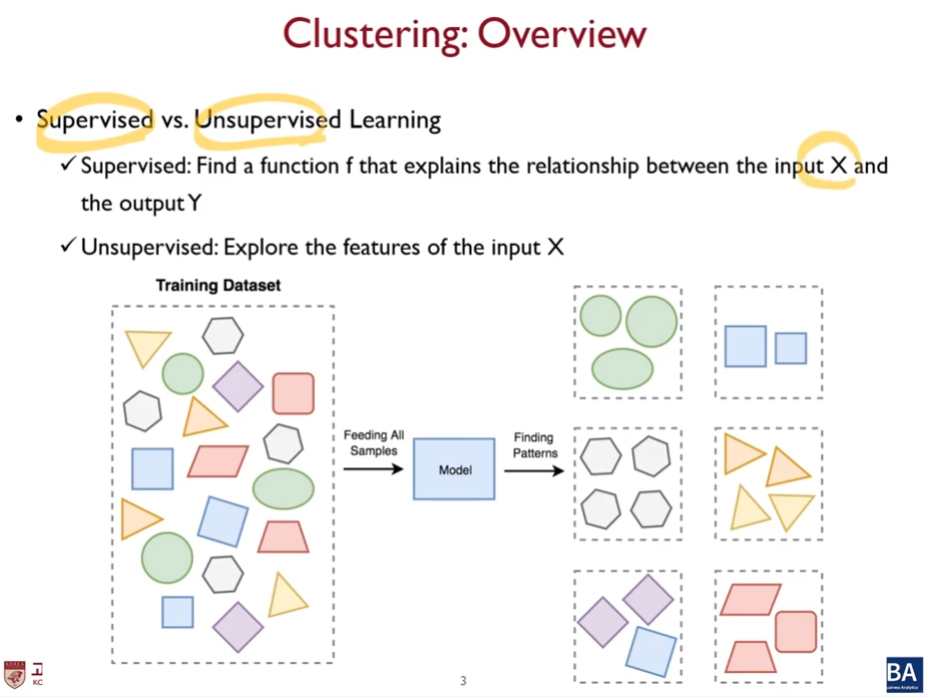
input x가 같은 내재적인 속성을 파악하는것.
특정 군집화 알고리즘에 의해서 비슷비슷한 객체들끼리 모아주는것.

객체들의 집단을 찾자. 두가지의 목적을 만족해야한다. 같은 그룹내에 있는 객체들은 유사해야한다.
서로 다른 그룹에 속해있다고 하면 각각을 달라야한다. 차이가 있어야한다.
군집간 분산을 최대화 하자.
정답이 없기 때문에 intra-custer variance, inter-cluster variance
군집화 타당성 지표를 계산하는 방식이 많다.
몇개의 클러스터가 최적이고 각각의 클러스터가.
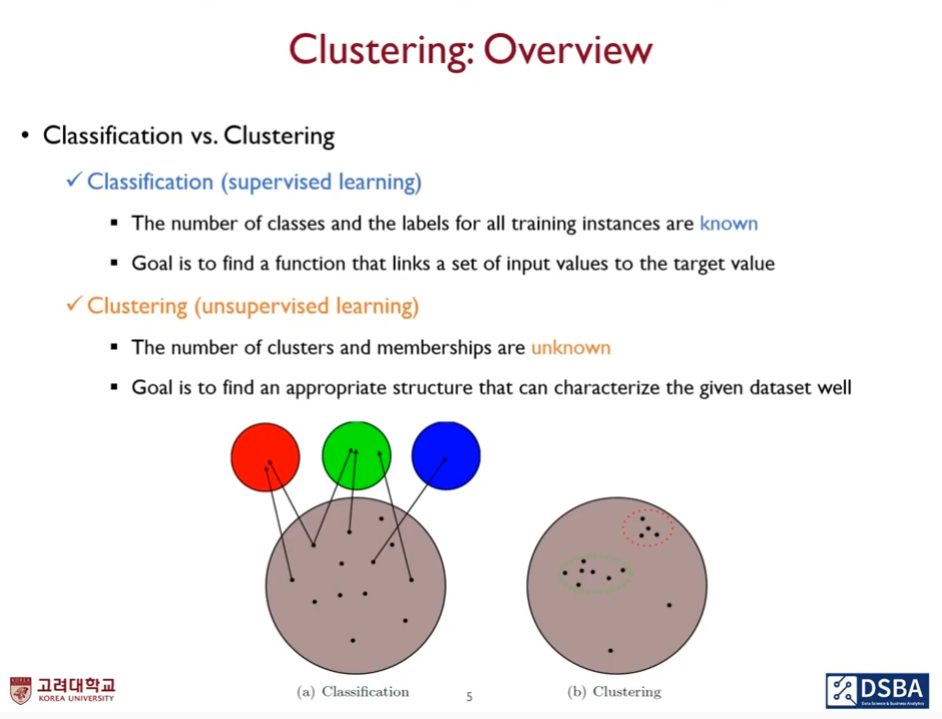
주어진 데이터셋의 본질적 structure를 파악할 수 있는 군집 개수와 membership을결정하자.

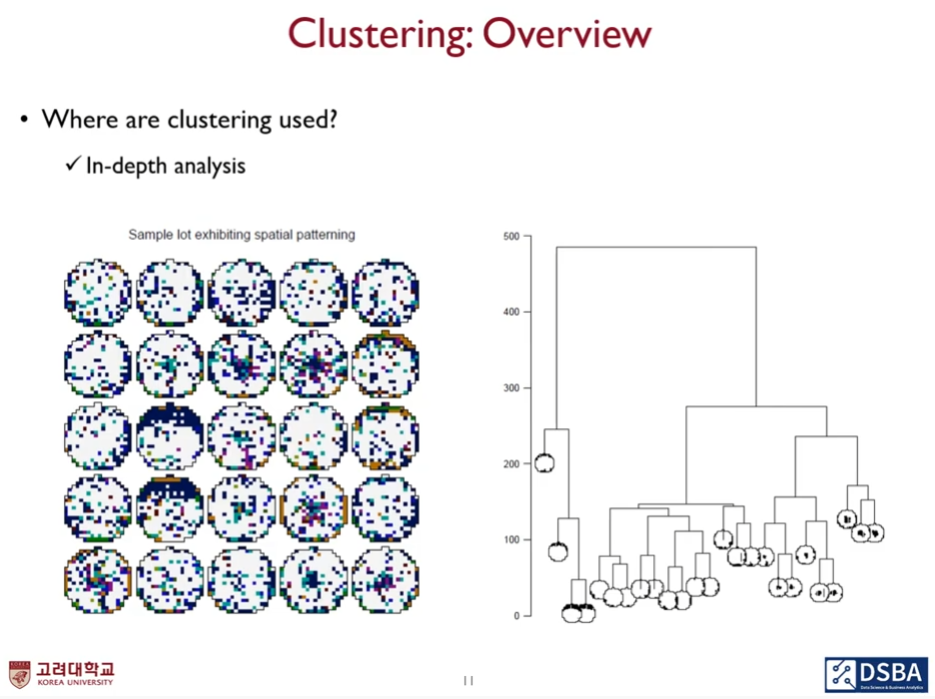
유사한 것들을 묶음으로 인해서 추가적인 분석이 될 수 있는

self-orgarizing map(SOM) 뉴럴넷 기반의 군집화와 시각화를 동시에 해 줄수 있는 알고리즘
GDP, IR, Export, Import 거시 경제 지표를 속성으로 각각의 국가들이 얼마만큼 유사한지 시각화
가까이에 위치한 나라는 경제지표로 봤을때 비슷하다. 멀리 떨어져있으면 다르다.

자산을 관리하는데 있어서 주식을 포트폴리오로 관리한다.
비슷한 움직임을 보였던 것을 군집화한다. 대표적인 주식들을 이용해서 포트폴리오 구성했더니 6개월 동안에 수익과 변동성 이용해서 향우 6개월 1년동안 수익을 잘 낼 수 있는지? 수익률 자체를 maximize하는 포트폴리오 변동성을 최소화하는 그룹을 목적에 맞게 대표 주식들을 이용해서 포트폴리오에 담아서 했더니 일반적인 변동성 수익률 뛰어 넘었다.

유사특허를 판별함으로써 분별할 수 있다.

회로와 관련된 특허
유사한 특허가 무엇인지..
레시피에 어떤 문제가 있었는지 도움을 준다.
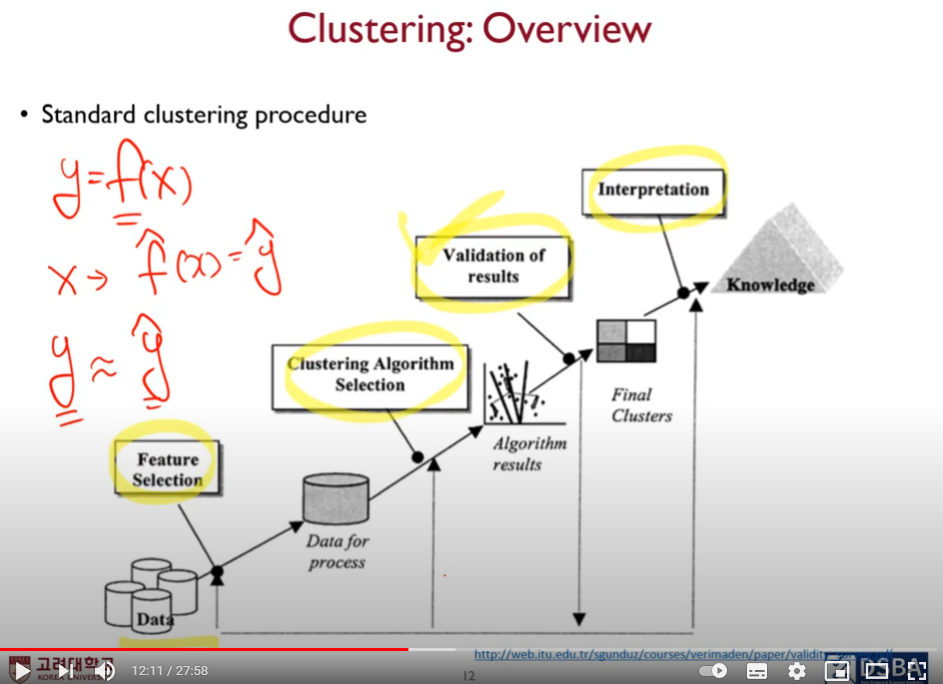
군집에 대한 결과물을 어떻게 검증할 것인가?
y = f(x)
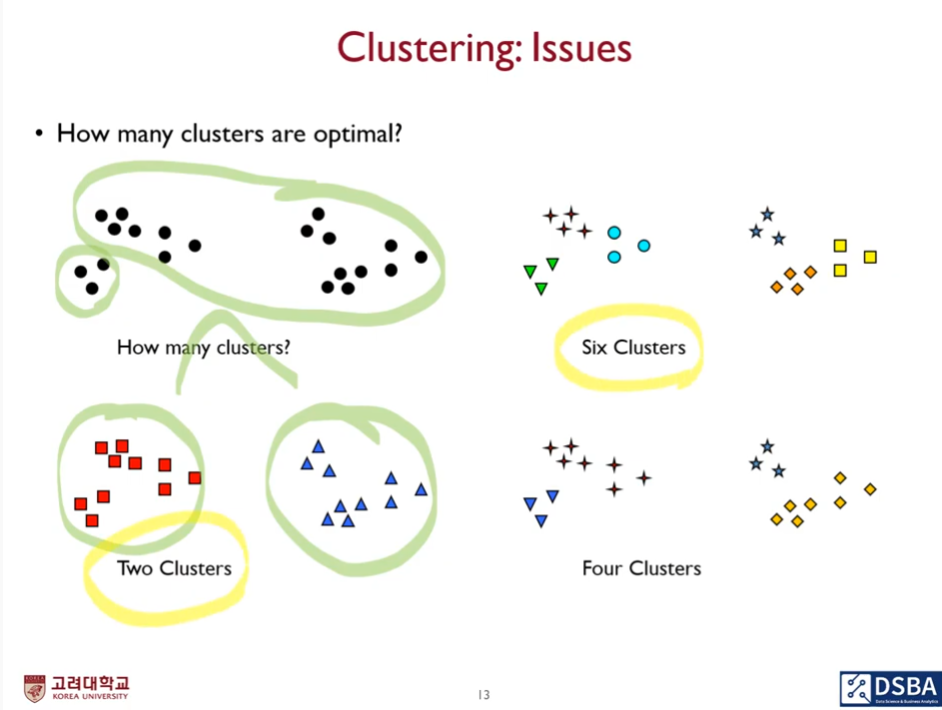
군집에 어떤 개수들이 포함되어있는지 모르겠다. optimal한 solution은 없다.
하나의 군집은 군집내에 속하는 객체들끼리 가까워지고 군집이 다르다면 멀리 떨어져야한다.
이것을 활용해서

몇개나 클러스터가 존재하는가?
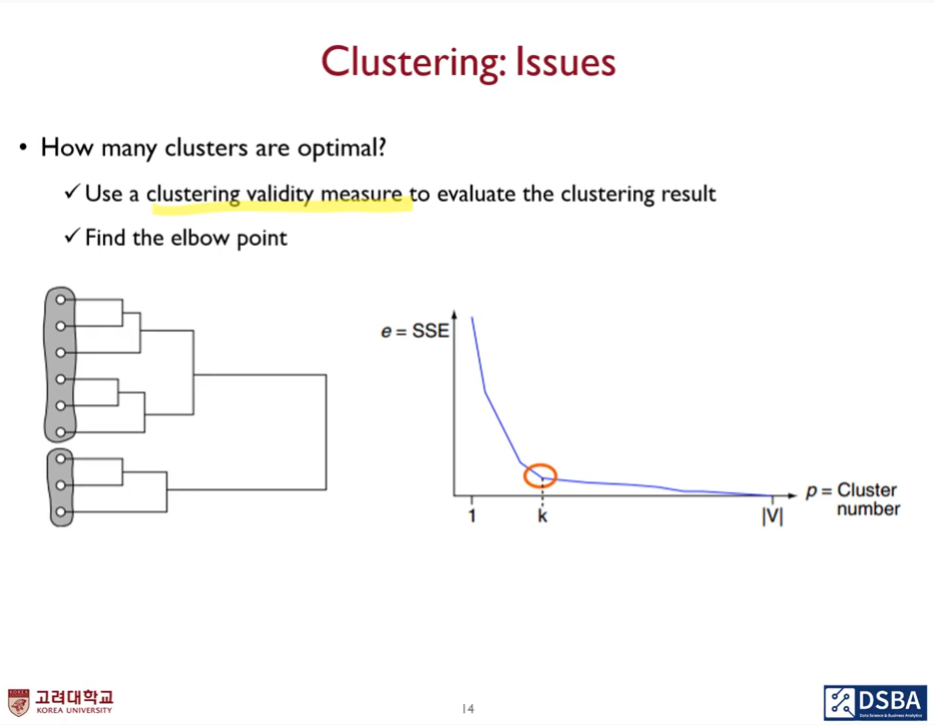
elbow point를 찾아서 이때의 군집의 개수를 최적으로 정하기도 한다.

External : 이미 클러스터의 맴버와 개수가 알려져 있다라고 가정하고 알고리즘이 생성한 결과물과 정답을 비교하는 방식이다. 비지도학습인데 정답이 있다는게 무슨뜻? --> 비현실적이다.
새로운 알고리즘을 개발했을때 이 알고리즘이 얼마나 잘하는지 평가하려면 이런 방식을 써야한다.(미리 클러스터 구조를 연구자가 생성해놓고) 연구용 논문용으로 쓰는것.
Internal 클러스터의 응집성을 강조하는 것.
Relative가 주로 사용된다. 두가지를 동시에 고려하기 때문에


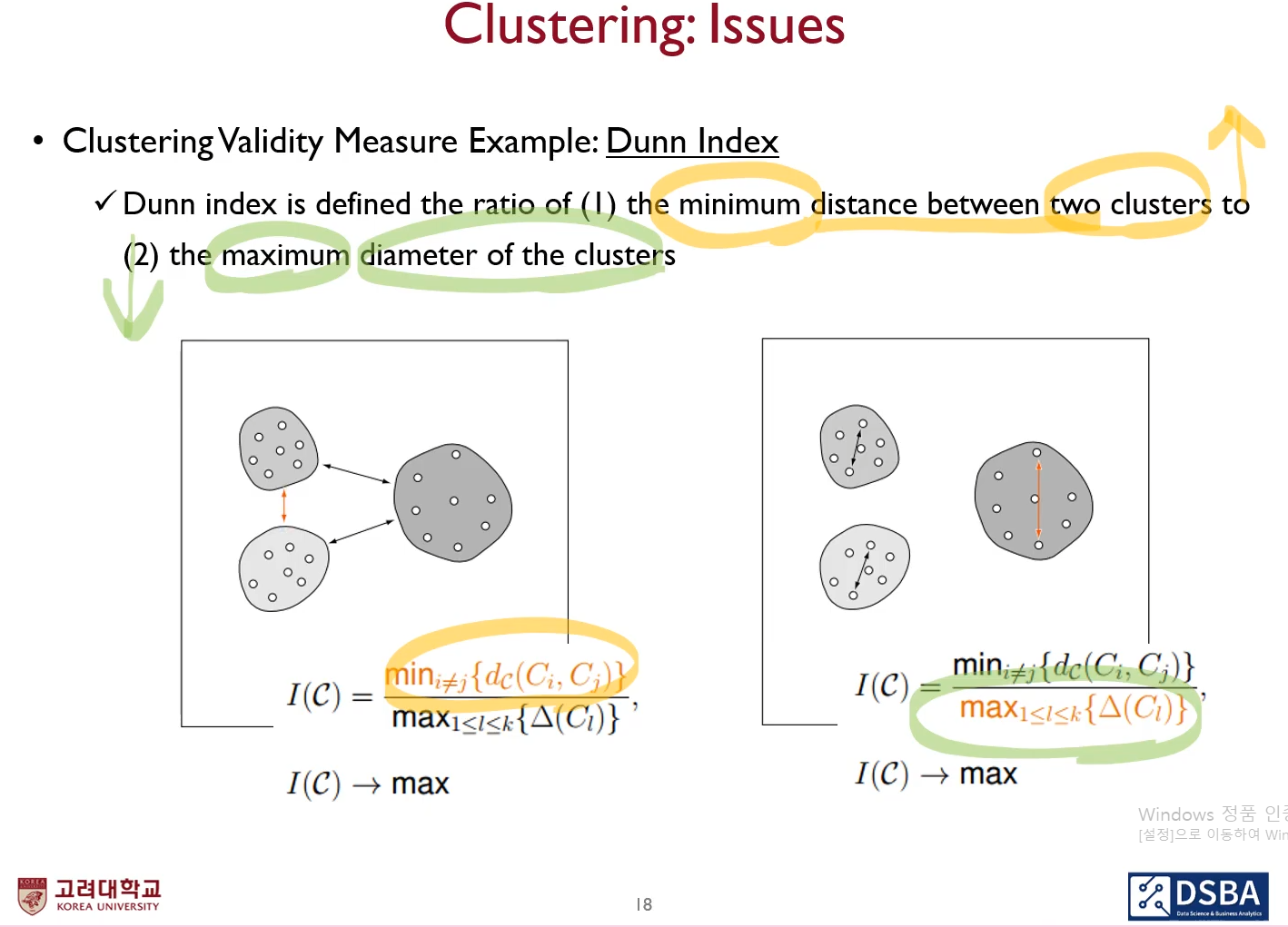
- 두 군집간의 거리를 어떻게 정의할 것인가?
각 군집에 존재하는 객체들 사이의 pairwised distance를 그릴 수 있다. 7*8=56개의 거리중 가장 작은것 을 택한다.
- 군집의 지름을 어떻게 정의할 것인가?
군집에 객체들 사이의 거리가 가장 먼 것을 택함.